


On Deep Learning and Farming: It's still 1915
What agriculture can teach us about AI development

Deep learning is about to experience its "fertilizer moment" – a revolution that will transform AI just as the Haber-Bosch process transformed agriculture.
For centuries, farmers were limited by natural constraints, with wheat yields stuck at ~1.2 tons per hectare. Then in 1913, everything changed. Today's yields exceed 8 tons – a 7× increase that would have seemed impossible under traditional farming methods.
Similarly, AI stands at the threshold of a 10-100× efficiency breakthrough with synthetic data becoming our "fertilizer" – concentrated learning nutrients that will fundamentally change what's possible with limited computational resources.
Building vs Growing: Two Ways to Create
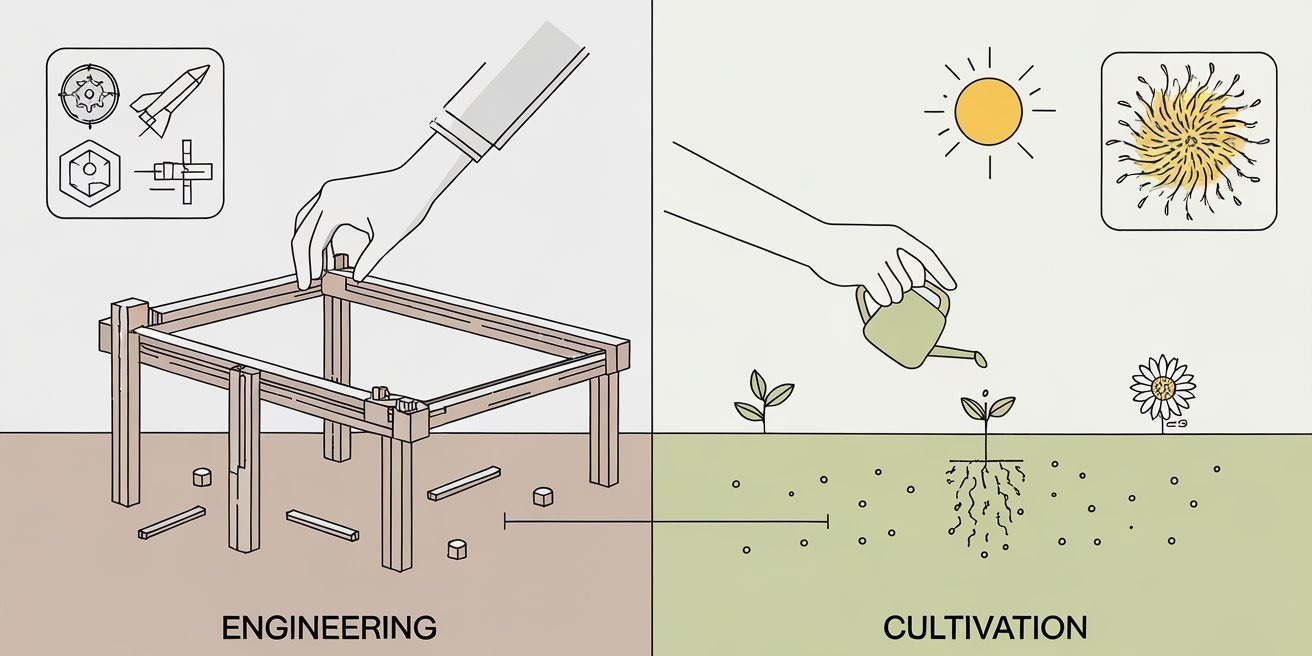
There are two fundamentally different ways to make things:
Engineering: You understand how the sub-components work and compose them deliberately - like building a table from wood and screws, we assemble piece by piece deliberately, this can be simple things or scaled up all the way to rockets and engines, database systems.
Cultivation: You can’t directly build a sunflower by assembling parts, but you can grow one by preparing soil, planting a seed, and providing water and sunlight. We provide the right environment for the outcome to emerge.
Deep learning is like cultivation. We prepare environments, plant architectures, and nurture them to grow capabilities.
We’re still early in understanding what truly feeds these systems.
The Farming Analogy Unpacked
This comparison works on multiple levels:
Neural architectures are like seeds - They contain the genetic potential that determines what capabilities can emerge. We go deeper on this in the following sections.
Data is like soil - Raw data is the soil, the place where the model extracts the patterns and information it needs to grow. The quantity and quality of this soil directly impacts how well our AI “plants” can develop.
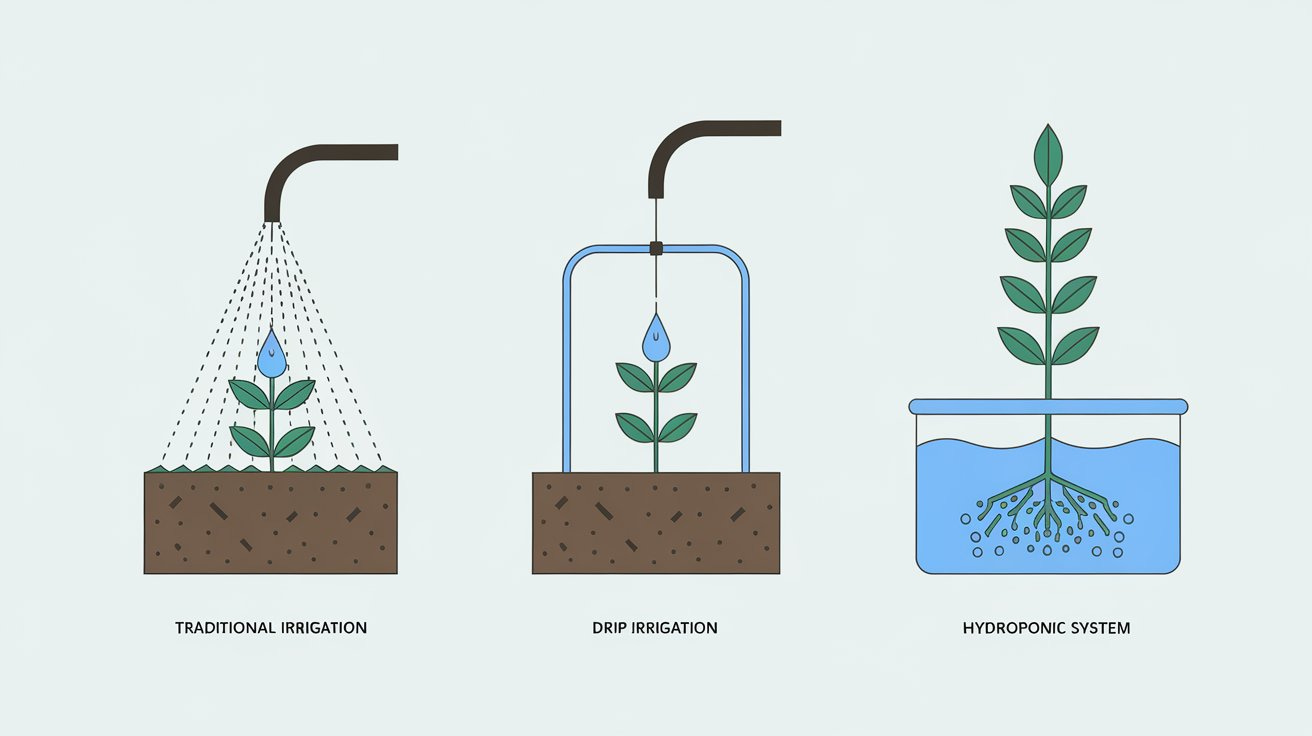
Optimization methods are like irrigation techniques - SGD is traditional farming (reliable but inefficient), Adam is drip irrigation (precise resource delivery), and second-order methods are hydroponics (expensive but enabling growth where traditional methods fail, training models that wouldn’t otherwise converge)
Hyperparameters are growing conditions - Learning rates are watering schedules, batch sizes are plot sizes, training duration is the growing season, determine the overall height/yeild.
Regularization is pruning - Techniques like dropout trim complexity to improve generalization, just as farmers remove unwanted growth to strengthen desired traits
Architectural Limits: Neural Growing Patterns

CNNs resemble bamboo – quick initial progress but plateau with inherent height limitations due to their fixed receptive fields
RNNs function like height-limited trees – solid structure but face gradient challenges that constrain their ultimate potential
Transformers are more like redwoods – capable of greater heights through their attention mechanisms, though still bound by architectural constraints
This shows why both scaling AND architecture matter. Just as perfect soil won’t make a shrub grow into a sequoia, architectural limitations determine what capabilities models can ultimately achieve, regardless of training resources.
Different Plants for Different Soils
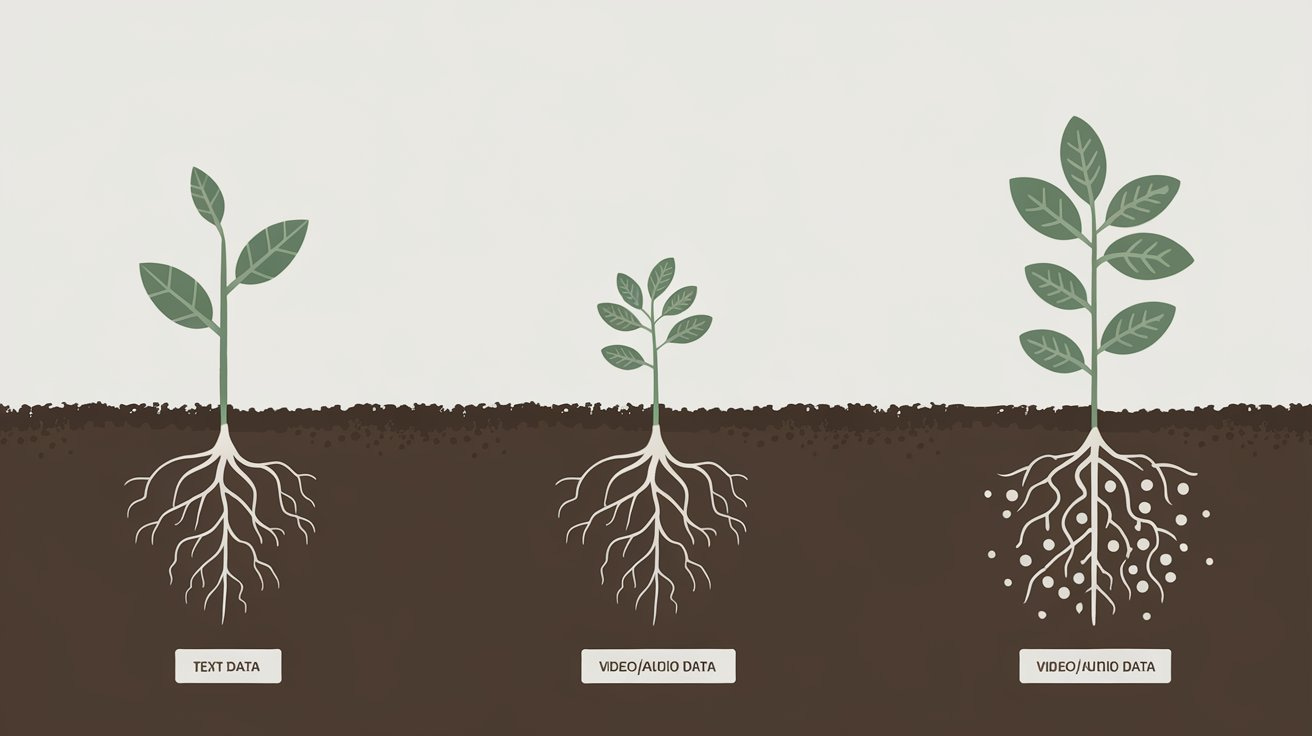
Architectures, like plant species, specialize for specific environments. We’ve mastered “text” soil (RNNs→Transformers) but lack equally effective architectures for video and audio data - we’re growing text-optimized plants in non-text soils.
Breakthroughs may come from specialized architectures for these untapped resources, like nitrogen-fixing plants evolved symbiotic relationships with soil bacteria. These video/audio architectures would scale as effectively as Transformers do for text.
{kind=link}
Nitrogen-fixing plants mostly resemble regular plants with specialized roots. Similarly, effective non-text architectures likely resemble Transformers with modified components (tokenizers, output layers).
These new crop varieties let us “grow” models in new non-textual “soil” types allowing us to grow in places previously considered non-arable
The Early Fertilizer Era of AI
We are now entering what can be described as “early-fertilizer” era,
Previously we have been working with what nature provides:
Collecting datasets “as they come” (raw soil)
Filtering out obvious problems (removing stones)
Scaling up quantity rather than transforming quality (using more land)
Breaking the Malthusian Barrier

Pre-fertilizer wheat yields remained at ~1.2 tons/hectare for centuries. No farming technique broke this ceiling. Malthus seemed right.
After Haber-Bosch (1913), yields hit 2.5 tons by 1950 and exceed 8 tons today - a 7× increase impossible under natural constraints.
The agricultural revolution didn’t happen by using more land or working harder. It came from understanding exactly what nutrients crops needed.
Similarly, AI training faces efficiency barriers. Traditional approaches need ~1 trillion tokens for GPT-4 performance. Synthetic data can potentially reduce this by 10-100×, fundamentally changing what’s possible with limited data - just as fertilizer transformed what could be grown on limited land.
The Key Insight: Fertilizer Isn’t Soil
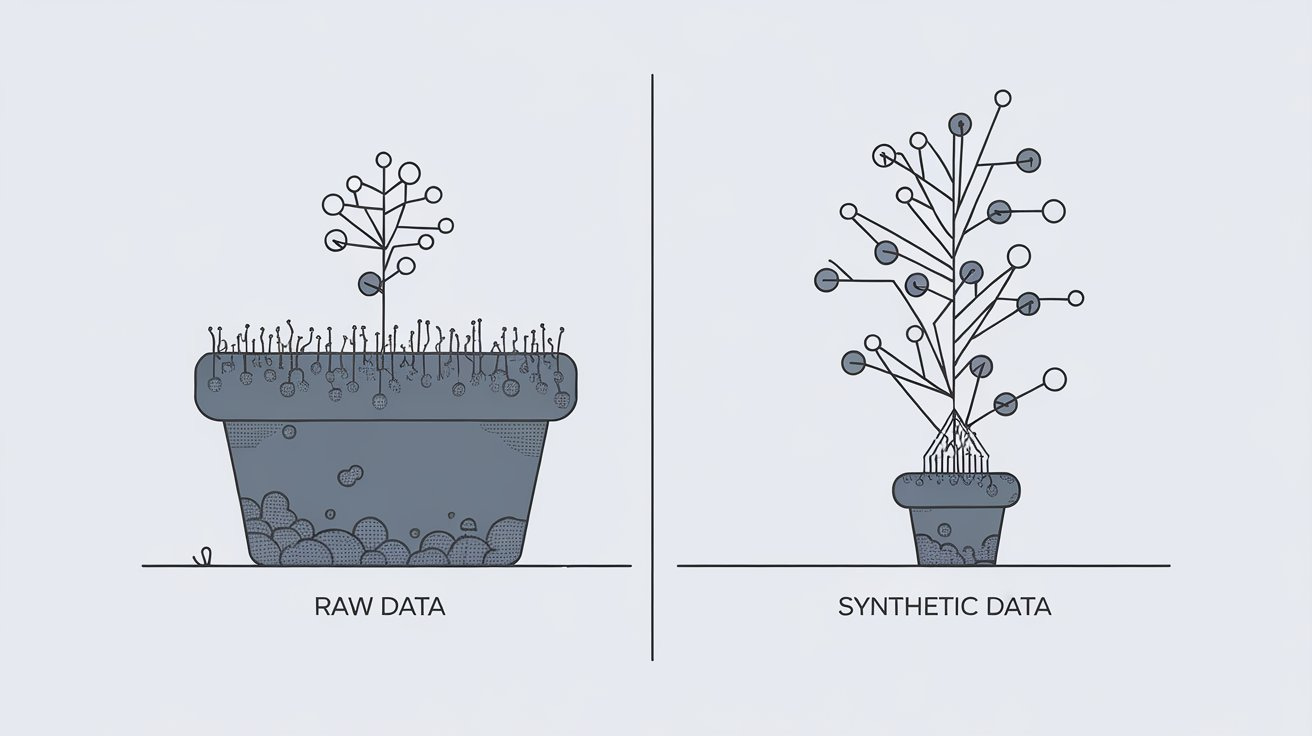
Synthetic examples don’t need to be “realistic” to be effective. Fertilizer looks nothing like soil, yet delivers precisely what plants need.
Recent results from the AI community provide striking evidence of this approach in action. The SYNTHETIC-1 dataset, which contains two million reasoning traces from symbolic mathematics verifiers and containerized test executions rather than human-written examples, demonstrates this principle clearly. When a 7B parameter model was trained on this dataset, it achieved 47.0% on the GPQA-Diamond graduate-level physics benchmark (compared to 29.8% for the base QWEN model) and 85.6% on MATH500 (versus 71.1% baseline).
Similarly, Phi-4 (14B parameters) outperforms GPT-4o on GPQA (56.1 vs 50.6) and MATH (80.4 vs 74.6) benchmarks by making synthetic data “the bulk of training data.” Microsoft’s experiments show models with 12 epochs of synthetic data consistently outperform those with more unique web tokens—concentrated learning fertilizer works better than more raw soil.
Other examples:
Stanford’s s1K dataset of just 1,000 carefully selected reasoning examples producing models that outperform others trained on 800× more data
Chain-of-thought prompting creating “deliberate thinking paths” unlike natural human text
Synthetic Prompts for In-Context Learning showing how artificially constructed examples improve performance without resembling natural data
The future isn’t more realistic synthetic data - it’s more effective synthetic data optimized for neural learning dynamics, not human recognizability.
Modern agriculture still needs industrial-scale operations that multiply output. But fertilizer created the real transformation - small fertilized plots outproducing vast traditional farms. Similarly for AI, while scaling matters, synthetic data creates breakthroughs that scaling alone cannot. The future will combine both: massive compute leveraging concentrated learning techniques to achieve otherwise impossible capabilities.
Testable Predictions
If this analogy holds, we should see these patterns emerge in the coming years:
Efficiency Breakthrough: By end of 2026, specialized models under 20B parameters trained on synthetic data will outperform general 100B+ models on reasoning benchmarks, building on what we’re seeing with Phi-4 versus GPT-4o.
Domain Pattern: Efficiency gains will emerge first in logical reasoning tasks (math, coding, physics) with 20-30× improvements before appearing in more subjective domains.
Compute Shift: By 2027, at least 3 out of 5 new state-of-the-art models will achieve their results while using 40% less compute than would be predicted by traditional scaling laws, specifically by incorporating synthetic data techniques as a central component of their training approach.
Quality Metrics: By 2027, the field will develop standardized measures for synthetic data quality beyond model performance, similar to fertilizer component measurements.
Specialization Gap: The performance gap between general models and specialized synthetically-trained ones will reach at least 25% on domain-specific tasks by mid-2026.
Implications and Future Directions
If this analogy holds, history suggests:
The Fertilizer Revolution - Engineered data will transform model performance with less raw material
Monoculture Risks - AI needs architectural diversity. iPhone zero-days are scary; “Transformer zero-days” would be worse - adversarial attacks compromising all similar AI simultaneously
Hybridization Breakthroughs - Major advances may come from crossing architectural approaches
Where Will Value Accrue?
Looking at agriculture’s evolution offers clues:
Seed Companies - AI differs as techniques aren’t easily patented, favoring those who operationalize quickly
Fertilizer Producers -Companies developing novel data generation could become crucial, manufacturing synthetic fertilizer will become critical. In today's landscape, this role is exemplified by key players like Scale AI, whose work in generating high-quality and synthetic data directly serves as the 'fertilizer' driving efficiency and new capabilities in AI models.
Farm Equipment Manufacturers (Compute Providers) - Companies providing the core compute hardware (GPUs, TPUs), like NVIDIA, are analogous to the manufacturers of tractors, combines, and other machinery during the agricultural revolution, such as International Harvester. This machinery didn't fundamentally change the crop's biology (like seeds or fertilizer) but enabled unprecedented scale, speed, and efficiency, making the entire revolution economically viable – and these equipment companies became immensely valuable (in the early part).
Value-Added Processing - ChatGPT is valuable like McDonald’s is valuable - both transform low-margin raw materials (beef/base models) into high-margin end products through consistent delivery, packaging, and user experience
Distribution Networks - Unlike agriculture, digital distribution is nearly costless (bits vs. biomass). However, inference still requires substantial infrastructure - you need “land” to grow models and different “land” to keep them producing value, making compute providers more like utility companies than distributors
Final Thoughts
A fundamental breakthrough will likely come from reimagining what constitutes effective training data.
When we truly understand the “nutrients” that feed neural networks, we’ll create synthetic training approaches that seem almost incomprehensible by today’s standards - concentrated learning signals that don’t resemble test data but drive exponential improvements in capability.
While innovations will continue across architectures, optimization methods, and deployment, this “fertilizer revolution” represents one of the most underexplored and potentially transformative frontiers in AI development.
Where the Analogy Breaks Down
Analogies are mental models with necessary simplifications. While the farming metaphor illuminates many aspects of AI development, several key differences deserve attention:
Compute as “fast forward” time machines - Unlike farming's fixed biological timelines, compute resources compress development cycles. TPUs and specialized hardware don't create different models; they simply accelerate the growth process. This has no agricultural parallel – farmers can't fast-forward an oak tree's growth from decades to days.
Distribution economics - Digital distribution has near-zero cost vs. physical agriculture's substantial logistics challenges
No decay - Unlike food, AI models don't rot; they remain functionally identical regardless of how many times they're copied
Expandable "land" (temporary) - We can gather datasets rapidly, resembling early frontier expansion, before eventual physical/regulatory constraints
Single-entity focus - We typically grow one massive "model tree" and then replicate it infinitely, rather than cultivating many separate plants simultaneously, this has implications for risk management.
Rapid improvements (temporary) - Models dramatically outperform predecessors, like early selective breeding before improvements became incremental
These differences primarily affect short-term dynamics. Long-term, parallels strengthen as AI development faces agriculture-like constraints: limited high-quality data, energy constraints, regulatory oversight, and diminishing returns from incremental improvements.
Despite these differences in timescales and mechanisms, agricultural history can still provide valuable insights into AI's potential evolutionary trajectory, especially as we enter the "fertilizer era" of synthetic data.
1915 indeed, thank you for this thoughtful perspective